I won't go into the method of collecting tweets using python; but instead direct you to this article that uses the Tweet Search script to mine for tweets and save them to a JSON file. This article launches right into the process of opening the saved JSON file.
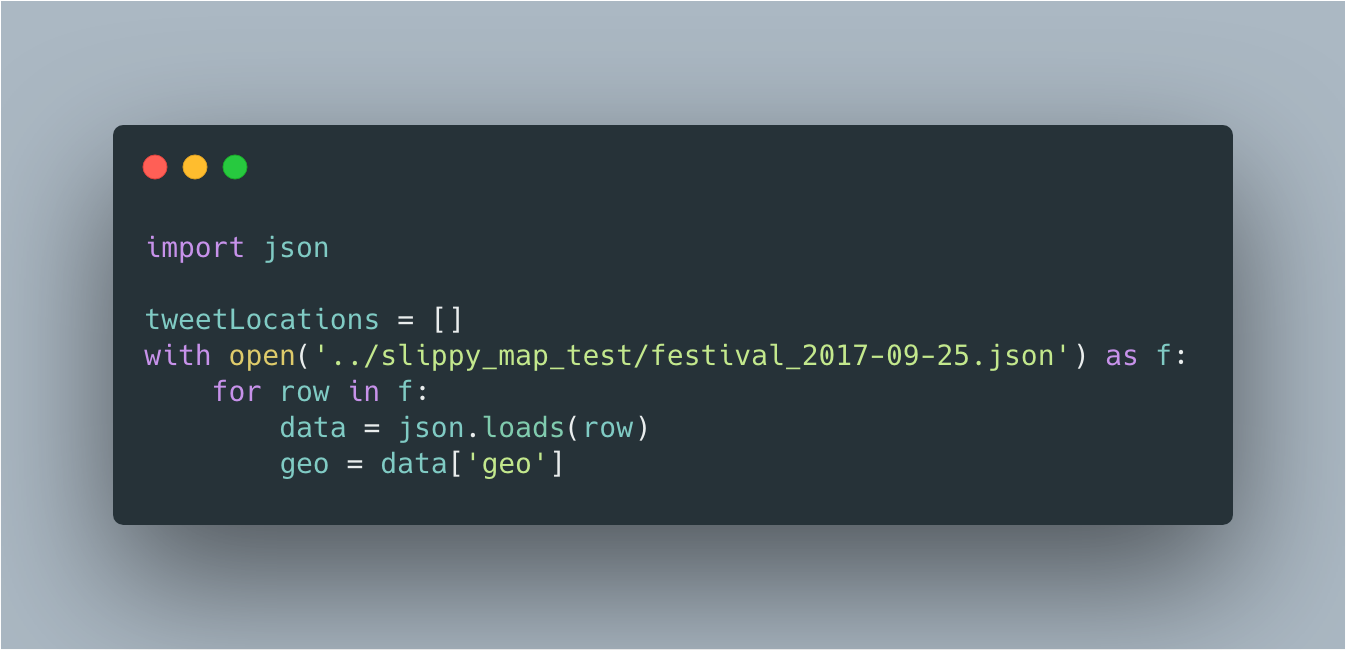
The first line: import json, loads Python’s library that handles JSON files. The following line, opens the JSON file (in this case it's Twitter data with the festival hashtag) and saves it to a variable, in this case it's called f (for file). Then, loop though each row of JSON objects in the file. The load() method parses (just like in Javascript) each row of tweets into a Python data structure and assigns it to a variable, called data. Each row has a key:value pair (in this case it's geo) that will be used to render the markers to the map.
If quite a few rows have null values, it's best to filter out these empty values before appending to an empty array. In this example, the coordinates had a significant number of empty values. Print geo (similar to console.log in Javascript) to verify in the Processing console that you've cleaned the correct data.
if geo is not None: tweetLocations.append(geo) print geo